Given a string s, partition the string into one or more substrings such that the characters in each substring are unique. That is, no letter appears in a single substring more than once.
Return the minimum number of substrings in such a partition.
Note that each character should belong to exactly one substring in a partition.
Example 1:
Input: s = "abacaba"
Output: 4
Explanation:
Two possible partitions are ("a","ba","cab","a") and ("ab","a","ca","ba").
It can be shown that 4 is the minimum number of substrings needed.
Example 2:
Input: s = "ssssss"
Output: 6
Explanation:
The only valid partition is ("s","s","s","s","s","s").
Constraints:
1 <= s.length <= 105sconsists of only English lowercase letters.
Solution: Greedy

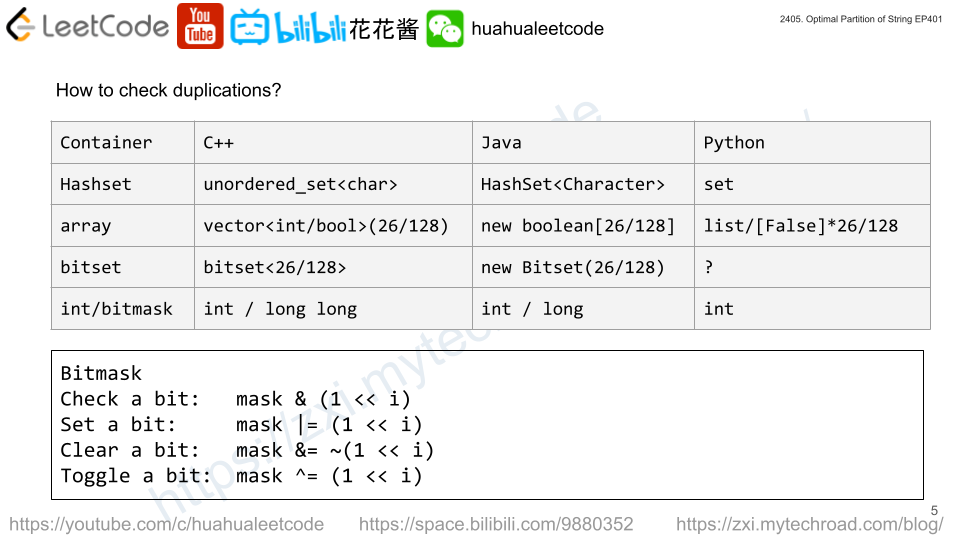
Extend the cur string as long as possible unless a duplicate character occurs.
You can use hashtable / array or bitmask to mark whether a character has been seen so far.
Time complexity: O(n)
Space complexity: O(1)
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
// Author: Huahua class Solution { public: int partitionString(string s) { unordered_set<char> m; int ans = 0; for (char c : s) { if (m.insert(c).second) continue; m.clear(); m.insert(c); ++ans; } return ans + 1; } }; |
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
// Author: Huahua class Solution { public: int partitionString(string s) { vector<int> m(26); int ans = 0; for (char c : s) { if (++m[c - 'a'] == 1) continue; fill(begin(m), end(m), 0); m[c - 'a'] = 1; ++ans; } return ans + 1; } }; |
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
// Author: Huahua class Solution { public: int partitionString(string s) { int mask = 0; int ans = 0; for (char c : s) { if (mask & (1 << (c - 'a'))) { mask = 0; ++ans; } mask |= 1 << (c - 'a'); } return ans + 1; } }; |