Given an array of words and a width maxWidth, format the text such that each line has exactly maxWidth characters and is fully (left and right) justified.
You should pack your words in a greedy approach; that is, pack as many words as you can in each line. Pad extra spaces ' ' when necessary so that each line has exactly maxWidth characters.
Extra spaces between words should be distributed as evenly as possible. If the number of spaces on a line do not divide evenly between words, the empty slots on the left will be assigned more spaces than the slots on the right.
For the last line of text, it should be left justified and no extra space is inserted between words.
Note:
- A word is defined as a character sequence consisting of non-space characters only.
- Each word’s length is guaranteed to be greater than 0 and not exceed maxWidth.
- The input array
words contains at least one word.
Example 1:
Input:
words = ["This", "is", "an", "example", "of", "text", "justification."]
maxWidth = 16
Output:
[
"This is an",
"example of text",
"justification. "
]
Example 2:
Input:
words = ["What","must","be","acknowledgment","shall","be"]
maxWidth = 16
Output:
[
"What must be",
"acknowledgment ",
"shall be "
]
Explanation: Note that the last line is "shall be " instead of "shall be",
because the last line must be left-justified instead of fully-justified.
Note that the second line is also left-justified becase it contains only one word.
Example 3:
Input:
words = ["Science","is","what","we","understand","well","enough","to","explain",
"to","a","computer.","Art","is","everything","else","we","do"]
maxWidth = 20
Output:
[
"Science is what we",
"understand well",
"enough to explain to",
"a computer. Art is",
"everything else we",
"do "
]
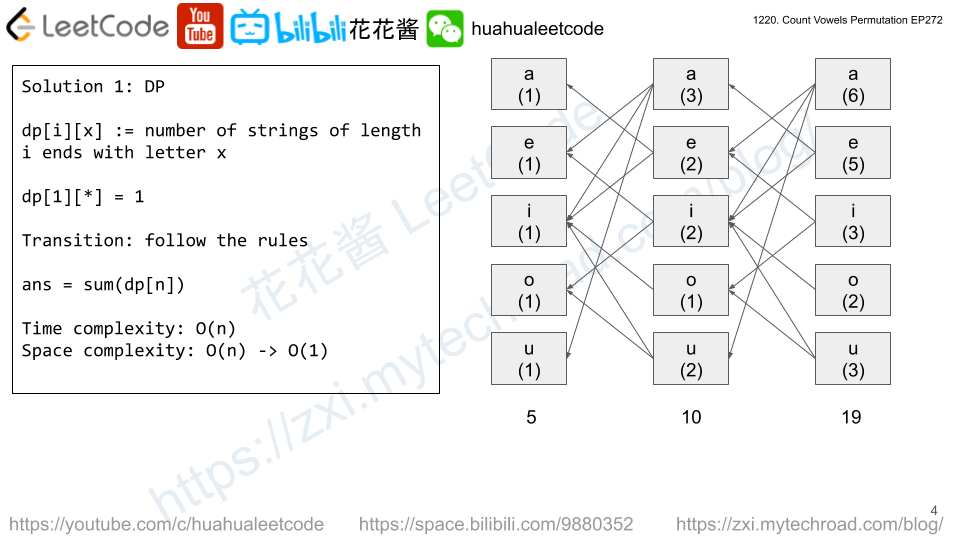
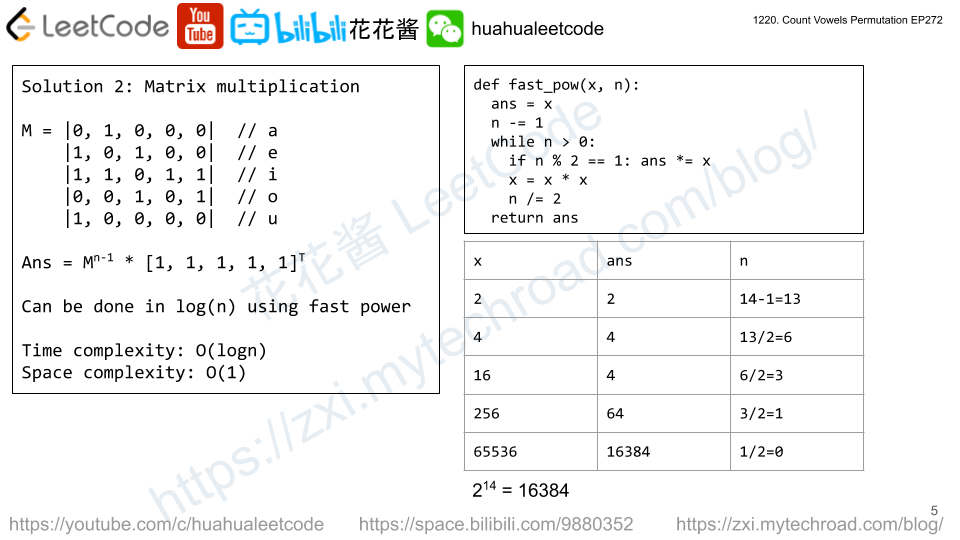
Solution: Simulation
Time complexity: O(sum(len(s))
Space complexity: O(sum(len(s))
C++
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
// Author: Huahua class Solution { public: vector<string> fullJustify(vector<string> &words, int L) { size_t i = 0, n = words.size(); vector<string> ans; while (i < n) { bool last_line = false; int ll = 0; vector<string_view> tw; while (ll <= L && i < n) { size_t wl = words[i].length(); int tll = ll + (tw.size() ? 1 : 0) + wl; if (tll > L) break; ll = tll; tw.push_back(string_view(words[i])); if (++i == n) last_line = true; if (ll == L) break; } string line; if (!last_line) { int tl = 0; for(const auto& w : tw) tl += w.length(); int avg_space = tw.size()==1 ? 0 : ((L-tl) / (tw.size() - 1)); int extra_space = tw.size()==1 ? 0 : (L - avg_space * (tw.size() - 1) - tl); for (const auto& w : tw) { if (line.length() > 0) { line.append(avg_space, ' '); if (extra_space > 0) { line += ' '; --extra_space; } } line += w; } } else { for (const auto& w : tw) { if (line.length() > 0) line += ' '; line += w; } } line.append(L - line.length(), ' '); ans.push_back(std::move(line)); } return ans; } }; |