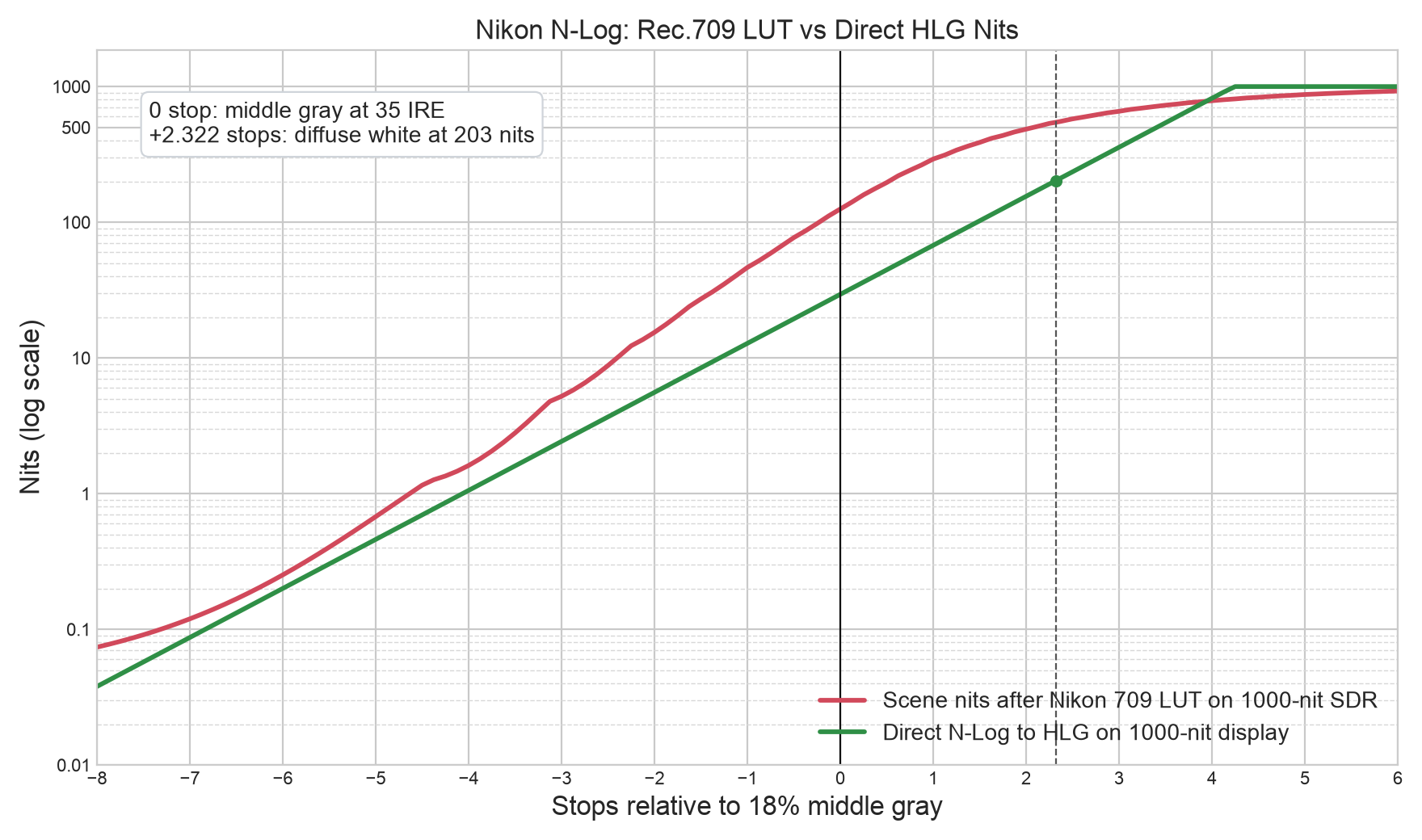
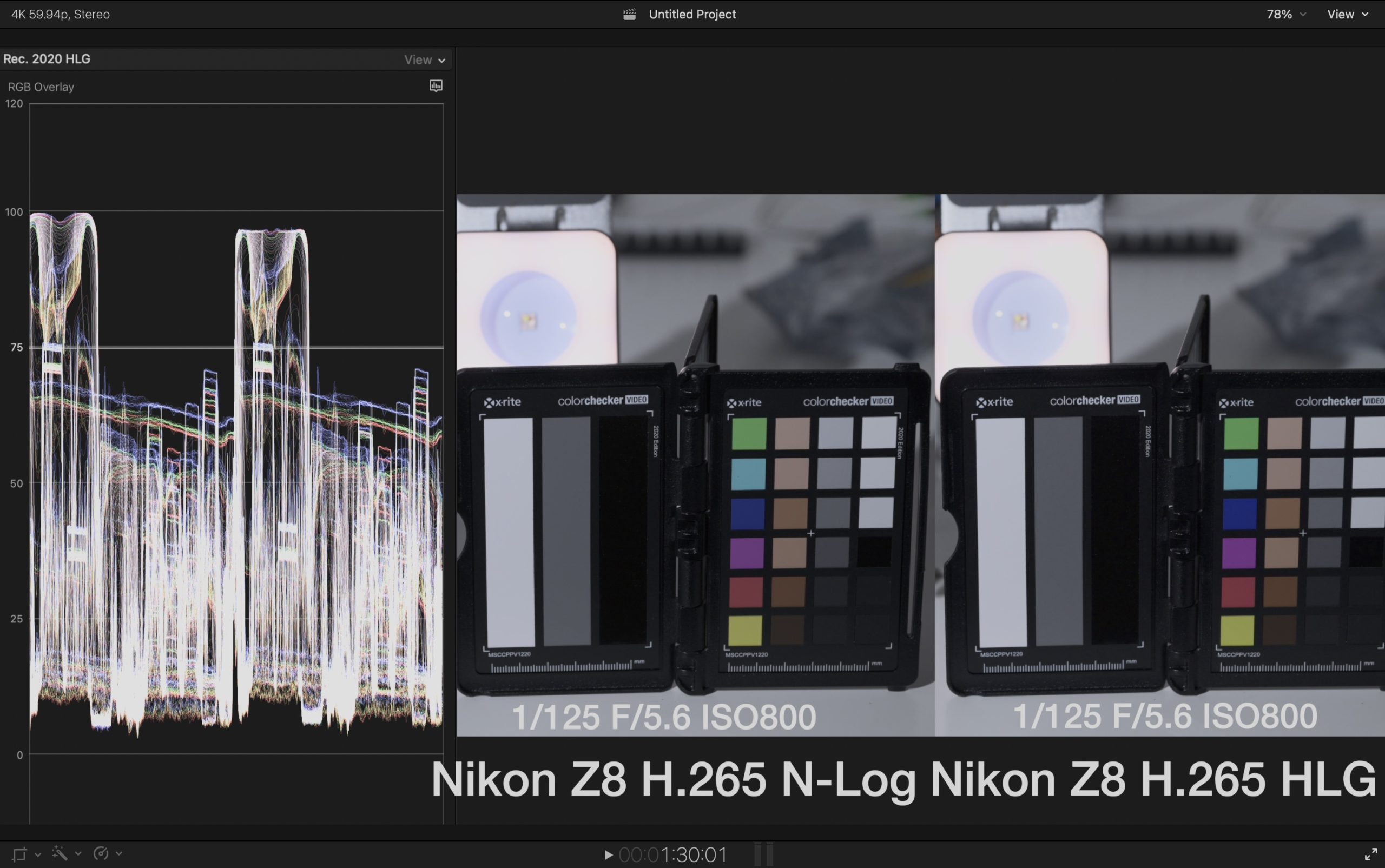
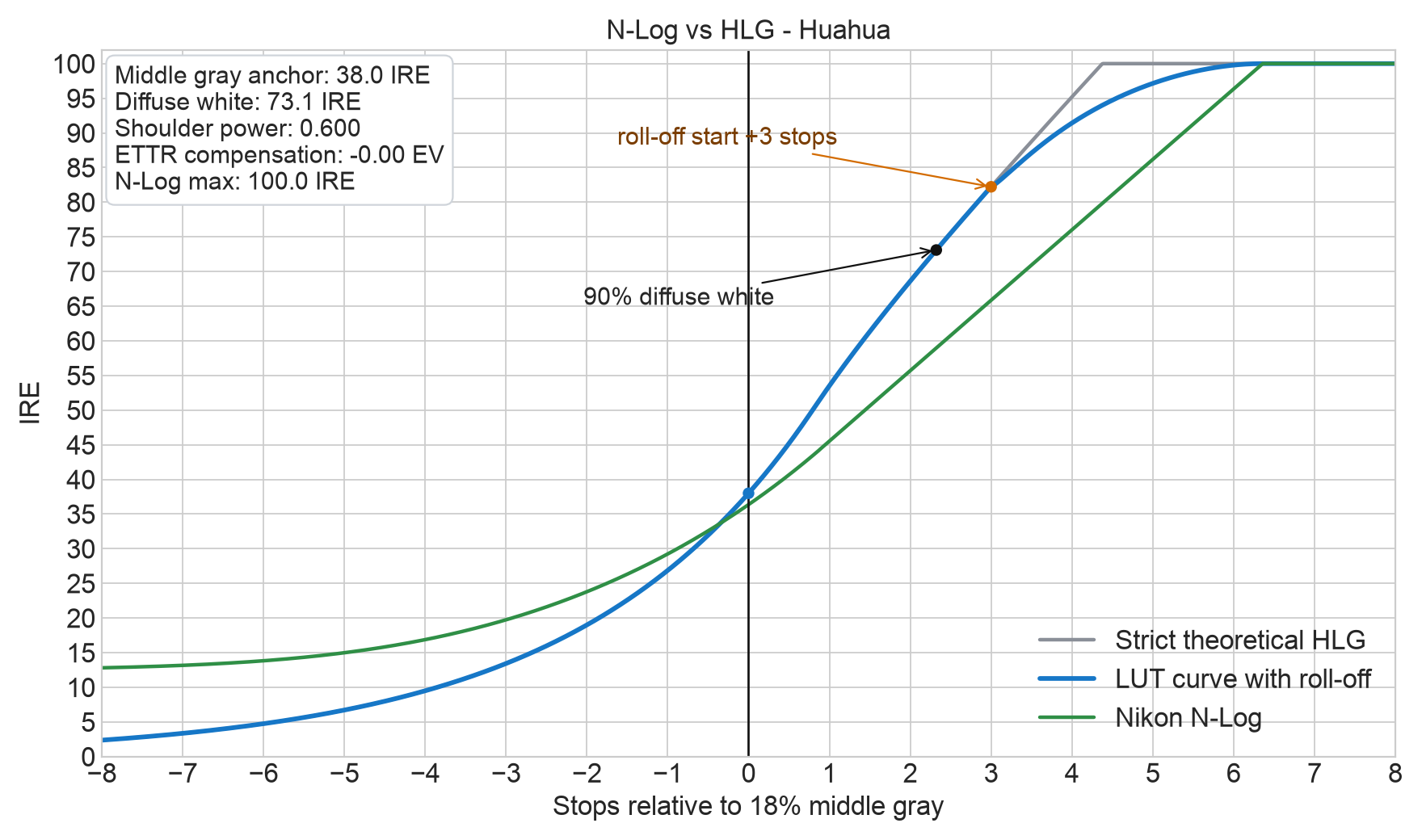
我做了一个新的 Final Cut Pro 插件:Huahua HDR LrC,当前版本1.12-46。它的目标很简单:让各家的Log素材在 Final Cut Pro 里更轻松地进入 HLG HDR 或 PQ HDR 工作流,不需要手动套一堆 LUT,也不需要反复搓色轮来调整曝光。
这个插件适合在 Wide Gamut HDR 时间线中使用,主要用于把相机 Log 素材转换到 HDR,同时提供一些类似 Lightroom / Camera Raw 的基础调色控制,例如曝光、对比度、高光、阴影、白场、黑场、自然饱和度和饱和度。它不是一个风格化 LUT 包,而是一个更偏实用的 HDR 转换和微调工具。
目前支持的输入格式包括:
- Nikon N-Log / Rec.2020
- Sony S-Log3 / S-Gamut3.Cine
- Sony S-Log3 / S-Gamut3
- Canon C-Log2 / Cinema Gamut
- HLG / Rec.2020
- PQ / Rec.2020
输出格式支持:
- Rec.2020 HLG
- PQ 1000 / 2000 / 4000 nits
如果你的素材是 Nikon N-Log、Sony S-Log3、Canon C-Log2,或者已经是 HLG / PQ HDR,这个插件可以直接在 FCP 里作为一个 Effect 使用。安装后会出现在:
Huahua HDR Tools / Huahua HDR LrC
它适合想快速完成 HDR 交付、YouTube HDR 上传、或者同时制作 HLG / PQ 版本的用户。
I made a new Final Cut Pro plug-in: Huahua HDR LrC, current version 1.12-46.
Its goal is simple: to make it easier to bring Log footage from different camera systems into an HLG HDR or PQ HDR workflow directly inside Final Cut Pro. No need to stack multiple LUTs manually, and no need to keep fighting the color wheels just to fix exposure.
The plug-in is designed for Wide Gamut HDR timelines. It mainly converts camera Log footage to HDR, while also providing Lightroom / Camera Raw style basic adjustment controls, including Exposure, Contrast, Highlights, Shadows, Whites, Blacks, Vibrance, and Saturation.
It is not a stylized LUT pack. It is more of a practical HDR technical conversion and trimming tool.
Currently supported input formats:
- Nikon N-Log / Rec.2020
- Sony S-Log3 / S-Gamut3.Cine
- Sony S-Log3 / S-Gamut3
- Canon C-Log2 / Cinema Gamut
- HLG / Rec.2020
- PQ / Rec.2020
Supported output formats:
- Rec.2020 HLG
- PQ 1000 / 2000 / 4000 nits
If your footage is Nikon N-Log, Sony S-Log3, Canon C-Log2, or already HLG / PQ HDR, you can use this plug-in directly as a Final Cut Pro Effect.
After installation, it appears under:
Huahua HDR Tools / Huahua HDR LrC
It is designed for users who want a faster HDR delivery workflow, whether for YouTube HDR uploads, HLG mastering, PQ mastering, or creating both HLG and PQ versions from the same edit.