Steam Machine 不是一台没有想法的机器。恰恰相反,它可能是 Valve 这些年硬件路线里最自然的一步:Steam Deck 证明了 SteamOS、Proton、AMD APU 和掌机形态可以组成一个足够顺滑的 PC 游戏入口;那么下一步,把屏幕拿掉,把性能拉高,把它塞进电视柜,不就成了客厅版 Steam Deck 吗?
问题是,硬件产品最怕“逻辑正确,时间错误”。
2026 年的 Steam Machine 面对的不是 2015 年那个 Linux 游戏生态尚未成熟的世界,也不是 2021 年 Steam Deck 刚出场时那个玩家渴望低价 PC 游戏入口的世界。它面对的是半导体价格上行、内存和 SSD 被 AI 需求挤压、主机平台已经进入成熟期、PC 显卡生态又被 AI 上采样重新洗牌的世界。
所以它的尴尬不只是“性能不够强”,而是每一个关键选择都踩在了时代的反方向上。
一台价格被时代推高的机器
Steam Machine 最初应该有一个很清晰的位置:比传统游戏 PC 更省心,比 PS5 更开放,比普通迷你主机更适合 Steam 游戏库。这个定位很漂亮,但它依赖一个前提:价格不能太高。
现在这个前提没了。
Steam Machine 512GB 无手柄版起价 1049 美元,2TB 无手柄版 1349 美元,带 Steam Controller 的 2TB 套装更高。这个价格一出来,Steam Machine 就不再是“主机替代品”,而是一台昂贵的迷你游戏 PC。
Valve 自己也解释过,它不像索尼、微软那样通过封闭生态补贴硬件。硬件接近成本价销售时,内存、存储、半导体供应链的波动都会直接体现在售价上。尤其在 AI 服务器大量吞噬 DRAM、NAND 和先进封装产能之后,消费级硬件厂商已经很难再假装供应链成本不存在。
这就是 Steam Machine 的第一重“生不逢时”:它本来需要一个甜点价格,但半导体涨价把它推到了高端价位。
Steam Deck 当年成功,很大程度上是因为它让人觉得“这价格买到这个体验,值”。Steam Machine 现在的问题正好相反:它让人先看到价格,再开始挑剔性能、显存、兼容性和上采样效果。
半定制 AMD 硬件,发布时已经显旧
Steam Machine 的核心硬件是半定制 AMD Zen 4 CPU 和 RDNA 3 GPU。纸面上看,Zen 4 六核十二线程并不差,RDNA 3 也不是古董。但问题在于,它发布在 2026 年。
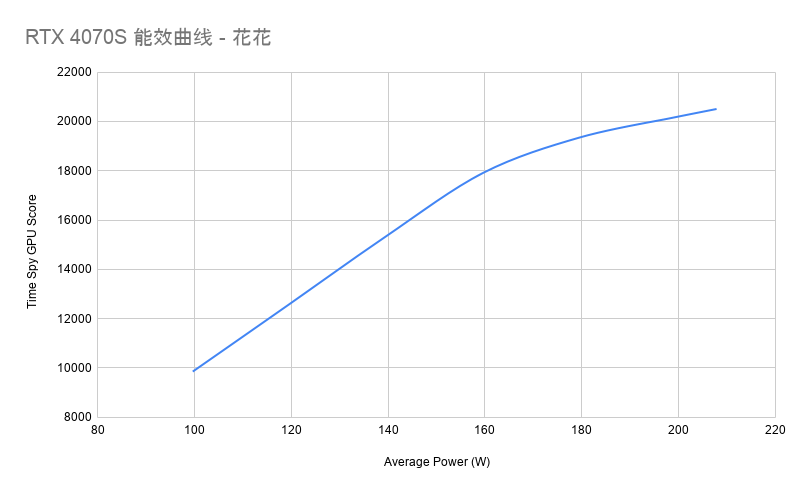
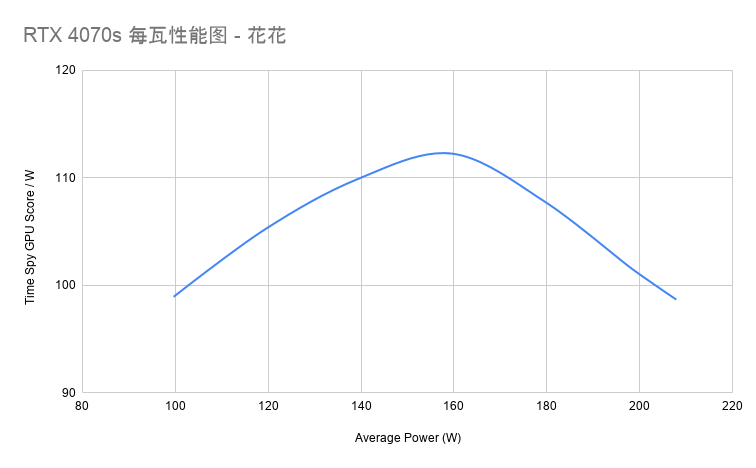
这颗 GPU 是 RDNA 3 架构,28 个 CU,8GB GDDR6 显存,约 110W TGP。放在小体积客厅设备里,这是一套合理配置;但放在 1049 美元起的价格下,它就显得不够兴奋了。
更尴尬的是,RDNA 3 是 2022 年底进入市场的架构。到 Steam Machine 正式登场时,AMD RDNA 4 已经不是新闻,PC DIY 市场也有更多新一代显卡可选。Steam Machine 的半定制芯片本来应该带来“为这个形态深度优化”的感觉,但结果更像是一颗被供应链和产品周期拖慢的移动级 GPU。
这和 PS5 不一样。PS5 的 Zen 2 和 RDNA 2 从今天看也老,但它是一个固定平台。开发者知道自己面对什么硬件,可以围绕统一内存、固定性能档位和主机 API 做长期优化。
Steam Machine 虽然长得像主机,运行的却是 PC 游戏库。它没有主机那么确定的优化红利,又没有 PC DIY 那么自由的升级空间。
这就形成了第二重错位:它定制了,但没有主机级生态;它开放了,但没有 DIY 级弹性。
AMD 生态绑定,让 FSR 的迟到更刺眼
Steam Machine 选择 AMD 并不奇怪。Steam Deck 已经证明,AMD、Linux 驱动、SteamOS 和 Proton 可以形成一套可控的技术栈。对 Valve 来说,继续押 AMD 是最稳的路径。
但到了客厅 4K 电视前,这种绑定开始露出另一面。
Steam Machine 的 GPU 不够强,所以它比高端 PC 更需要上采样。问题是,上采样生态里,Nvidia 的 DLSS 已经从“提升帧率的小技巧”变成了图形体验的一部分。DLSS 4 / 4.5 强化 AI 上采样、时序稳定性和多帧生成能力,很多 PC 玩家买显卡时已经默认把 DLSS 当成性能的一部分。
AMD 这边的 FSR 当然也在进步,但节奏更被动。FSR 4 最初主要面向 RDNA 4 / Radeon RX 9000 系列,RDNA 3 支持需要后续扩展。Valve 和 AMD 合作把 FSR 4 带到 Steam Machine 是好消息,但它同时说明:Steam Machine 最需要 FSR 4 的时候,FSR 4 并不是开箱即用、天然完整的优势。
这对 Steam Machine 很致命。因为它的性能叙事不能只靠原生渲染,必须靠上采样把 1440p、4K、光追这些体验补起来。PS5 Pro 有 PSSR,PC DIY 可以选 DLSS,Steam Machine 则被绑定在 AMD 的 FSR 节奏上。
一句话说:Steam Machine 最需要“软件第二块 GPU”的时候,它没有拿到最强的那块。
功耗约束:它像主机一样克制,却不像主机一样便宜
功耗是理解 Steam Machine 的关键。
Steam Machine 的 CPU 约 30W TDP,GPU 约 110W TGP。整机再加上内存、SSD、主板、无线模块和风扇,大致就是一台 150W 级的小型客厅 PC。它的体积很小,散热依赖单个 120mm 风扇。小、冷静、安静,很适合放进电视柜,这是它真实的优点。
Valve 显然不是想做一台暴力性能 PC,而是想做一台你可以长期放在客厅里、不吵、不热、不难看的 Steam 主机。
问题是,消费者并不会只按功耗买单。到了 1049 美元这个价位,玩家会本能地问:如果我付的是 PC 价格,为什么不能要 PC 性能?如果我接受主机形态,为什么不能要主机价格?
PS5 的整机电源规格更高,PS5 Pro 的最大功耗口径也更高,但主机平台能把这些功耗换成确定体验。开发者知道硬件边界,玩家也知道自己买到的是一个稳定目标。PC DIY 更简单:你愿意上 200W、300W 显卡,就能换更高性能;你愿意选 Nvidia,还能吃 DLSS 的生态红利。
Steam Machine 卡在中间。它像主机一样克制功耗,像迷你 PC 一样压缩散热,又像开放 PC 一样承担兼容性和设置成本。它的功耗策略是优雅的,但它的价格让这种优雅变成了妥协。
横向对比:Steam Machine 的参照系太残酷
Steam Machine 最大的问题不是打不过 2000 美元的高端 PC,而是它在 1000 美元上下这个价位,很难讲清楚自己为什么比 PS5、PS5 Pro 或 RTX 5060 / 5060 Ti DIY PC 更值得买。
| 方案 | 价格区间 | 核心硬件 | 图形生态 | 功耗/体积 | 主要优势 | 主要问题 |
|---|
| Steam Machine 512GB | 1049 美元起 | Zen 4 6C/12T + RDNA 3 半定制 GPU,28 CU,8GB GDDR6 | FSR;FSR 4 需要后续适配 | GPU 约 110W,小体积,低噪音 | SteamOS、客厅友好、小巧安静、Steam 库继承 | 贵;GPU 架构偏旧;8GB 显存;没有 DLSS;性能上限被功耗锁住 |
| PS5 | 约 499-599 美元档 | Zen 2 + RDNA 2 定制 SoC,16GB GDDR6 统一内存 | 固定平台优化 | 主机体积,功耗余量更大 | 便宜、省心、游戏优化稳定 | 封闭生态;不能自由升级;PC 游戏库不可直接继承 |
| PS5 Pro | 约 699-899 美元档 | 强化版 PlayStation SoC,更强 GPU | PSSR + 主机优化 | 主机体积,功耗更高 | 比 PS5 更强,仍然省心 | 仍是封闭平台;价格接近入门游戏 PC |
| 同价位 DIY PC:RTX 5060 | 约 900-1100 美元 | Ryzen 5 / Core i5 + RTX 5060 8GB,约 145W 级显卡 | DLSS 4 / 4.5、Frame Generation、Nvidia 驱动生态 | 更大、更耗电、可升级 | 性能和兼容性更自由;DLSS 明显加分 | 8GB 显存仍然紧;需要自己装机和维护 |
| 同价位 DIY PC:RTX 5060 Ti 16GB | 约 1050-1250 美元,视行情浮动 | Ryzen 5 / Core i5 + RTX 5060 Ti 16GB,约 180W 级显卡 | DLSS 4 / 4.5,16GB 显存更稳 | 更大、更耗电、可升级 | 1440p 更稳;显存优势明显;AI 上采样生态强 | 价格受内存/显卡行情影响;不如 Steam Machine 小巧安静 |
这张表真正说明的问题,不是 Steam Machine 一无是处,而是它的参照系太残酷。和 PS5 比,它贵得像 PC;和同价位 PC 比,它又弱得像主机。
RTX 5060 DIY PC 至少能拿到 DLSS、完整 Windows 游戏兼容性和后续升级空间。RTX 5060 Ti 16GB 方案则进一步补上了显存短板。Steam Machine 的优势是小、静、顺滑、SteamOS 一体化,但这些优势必须和 1049 美元的起售价一起被审视。
到了这个价位,玩家不会只问它是不是优雅,而会问:为什么我不买 PS5 Pro,或者再加一点直接上 5060 Ti 16GB 台式机?
对比 PS5:Steam Machine 输在确定性
PS5 的硬件并不新。基础版 PS5 是 Zen 2 CPU、RDNA 2 GPU、16GB GDDR6 统一内存。单看架构,它比 Steam Machine 更老。
但主机从来不是靠参数表赢 PC。PS5 赢在确定性:买回来,插上电视,进游戏,开发者已经替你做了绝大多数取舍。画质模式、性能模式、手柄反馈、休眠恢复、更新路径,都是平台体验的一部分。
Steam Machine 虽然也想做这种体验,但它毕竟还是 PC。它要面对不同游戏的 Linux 兼容性、Proton 差异、图形设置、显存爆掉、FSR 支持情况、手柄适配和桌面模式。Valve 很擅长长期更新,Steam Deck 就是例子,但上市那一刻,Steam Machine 不能只靠“以后会更好”说服大众。
尤其当 PS5 价格明显更低时,Steam Machine 的开放性就必须非常有吸引力。问题是,对很多客厅玩家来说,开放不是第一需求,省心才是。
PS5 的封闭是缺点,也是它的护城河。Steam Machine 的开放是优点,也是它的负担。
对比 PC DIY:Steam Machine 输在上限
如果说 PS5 从“省心”这一端夹住 Steam Machine,那么 PC DIY 就从“性能上限”这一端夹住它。
PC DIY 的缺点很明显:大、吵、复杂、贵,需要自己选配件、装系统、调驱动。但它至少给了用户一条清晰路径:花更多钱,得到更多性能;以后不够了,还能换显卡、换 CPU、加内存。
Steam Machine 也贵,但它把很多东西封装死了。你买到的是 Valve 精心设计的小盒子,也是一个功耗、散热、显存和 GPU 规格都固定的边界。它比 DIY 优雅,却不如 DIY 放肆;它比主机开放,却不如主机便宜。
更现实的是,RTX 5060 / 5060 Ti 这个级别的 PC 也不是什么极端发烧配置。它们就是 Steam Machine 必须面对的同价位普通对手。5060 级别至少能靠 DLSS 扩展性能边界;5060 Ti 16GB 则直接在显存上拉开差距。Steam Machine 的 8GB GDDR6 在今天已经需要不断解释,而 16GB 显存的存在让这种解释更尴尬。
这就是它最难讲清楚的地方:Steam Machine 的优点都是真的,但每个优点旁边都有一个更强的参照物。
想省心?PS5 更省心。
想性能?DIY PC 更强。
想小体积?迷你 PC 和游戏本也能竞争。
想 SteamOS?Steam Deck 已经更便宜地证明过这个价值。
想客厅 PC?Steam Machine 是最漂亮的方案之一,但价格又把门槛抬得太高。
它不是没有价值,只是太挑用户
公平地说,Steam Machine 不是一台烂机器。
它的小体积、低噪音、SteamOS、Steam Controller、Steam 库继承、Proton 生态和桌面模式,对一部分玩家非常有吸引力。尤其是那些已经深度拥有 Steam 游戏库,又不想在客厅摆一台传统 PC 的用户,Steam Machine 可能正中需求。
而且 Valve 的长期维护能力值得尊重。Steam Deck 早期也并不完美,但靠系统更新、兼容性改进和社区支持,逐渐变成了非常成熟的设备。Steam Machine 未来也可能走同样路线。
只是博客的判断不该只看“未来可能变好”,而要看它出生时面对的市场。
2026 年的 Steam Machine 太难了。半导体涨价让它失去低价优势;AMD 半定制 RDNA 3 让它发布即显旧;FSR 4 的迟到和 DLSS 4.5 的领先让它的软件补偿不够强;低功耗小体积设计让它优雅安静,也限制了性能上限。
它不是没有灵魂。它只是生在了一个对硬件极其苛刻的年份。
Steam Machine 最后的悲剧感在于:它几乎每一步都说得通。选择 AMD,说得通;控制功耗,说得通;坚持开放生态,说得通;不补贴硬件,也说得通。但这些正确的小决定合在一起,却组成了一个很难大卖的产品。
有些机器失败,是因为方向错了。Steam Machine 更像是方向没错,只是世界已经换了价格表、换了显卡生态、换了玩家期待。
它应该是 Steam Deck 成功之后最自然的一步。可自然,不等于正好。