You are given two strings of the same length s1 and s2 and a string baseStr.
We say s1[i] and s2[i] are equivalent characters.
- For example, if
s1 = "abc"ands2 = "cde", then we have'a' == 'c','b' == 'd', and'c' == 'e'.
Equivalent characters follow the usual rules of any equivalence relation:
- Reflexivity:
'a' == 'a'. - Symmetry:
'a' == 'b'implies'b' == 'a'. - Transitivity:
'a' == 'b'and'b' == 'c'implies'a' == 'c'.
For example, given the equivalency information from s1 = "abc" and s2 = "cde", "acd" and "aab" are equivalent strings of baseStr = "eed", and "aab" is the lexicographically smallest equivalent string of baseStr.
Return the lexicographically smallest equivalent string of baseStr by using the equivalency information from s1 and s2.
Example 1:
Input: s1 = "parker", s2 = "morris", baseStr = "parser" Output: "makkek" Explanation: Based on the equivalency information in s1 and s2, we can group their characters as [m,p], [a,o], [k,r,s], [e,i]. The characters in each group are equivalent and sorted in lexicographical order. So the answer is "makkek".
Example 2:
Input: s1 = "hello", s2 = "world", baseStr = "hold" Output: "hdld" Explanation: Based on the equivalency information in s1 and s2, we can group their characters as [h,w], [d,e,o], [l,r]. So only the second letter 'o' in baseStr is changed to 'd', the answer is "hdld".
Example 3:
|
1 2 3 |
<strong>Input:</strong> s1 = "leetcode", s2 = "programs", baseStr = "sourcecode" <strong>Output:</strong> "aauaaaaada" <strong>Explanation:</strong> We group the equivalent characters in s1 and s2 as [a,o,e,r,s,c], [l,p], [g,t] and [d,m], thus all letters in baseStr except 'u' and 'd' are transformed to 'a', the answer is "aauaaaaada". |
Constraints:
1 <= s1.length, s2.length, baseStr <= 1000s1.length == s2.lengths1,s2, andbaseStrconsist of lowercase English letters.
Solution: Union Find
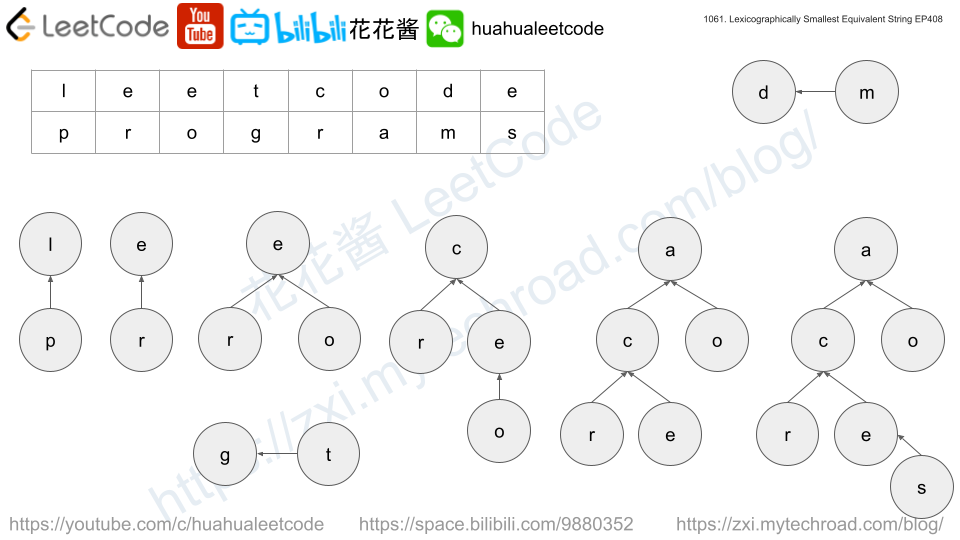
Time complexity: O(n + m)
Space complexity: O(1)
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
// Author: Huahua class Solution { public: string smallestEquivalentString(string s1, string s2, string baseStr) { vector<int> p(26); iota(begin(p), end(p), 0); function<int(int)> find = [&](int x) { return p[x] == x ? x : p[x] = find(p[x]); }; for (int i = 0; i < s1.length(); ++i) { int r1 = find(s1[i] - 'a'); int r2 = find(s2[i] - 'a'); if (r2 < r1) swap(r1, r2); p[r2] = r1; } string ans(baseStr); for (int i = 0; i < baseStr.length(); ++i) { ans[i] = find(baseStr[i] - 'a') + 'a'; } return ans; } }; |
请尊重作者的劳动成果,转载请注明出处!花花保留对文章/视频的所有权利。
如果您喜欢这篇文章/视频,欢迎您捐赠花花。
If you like my articles / videos, donations are welcome.
Paypal


Venmo
huahualeetcode
huahualeetcode

微信打赏

Be First to Comment