May 6, 2024
Return the number of distinct non-empty substrings of text that can be written as the concatenation of some string with itself.
Example 1:
Input: text = "abcabcabc" Output: 3 Explanation: The 3 substrings are "abcabc", "bcabca" and "cabcab".
Example 2:
Input: text = "leetcodeleetcode" Output: 2 Explanation: The 2 substrings are "ee" and "leetcodeleetcode".
Constraints:
1 <= text.length <= 2000text has only lowercase English letters.Try all possible substrings
Time complexity: O(n^3)
Space complexity: O(n^2)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
// Author: Huahua class Solution { public: int distinctEchoSubstrings(string text) { const int n = text.length(); string_view t(text); unordered_set<string_view> s; for (int k = 1; k <= n / 2; ++k) for (int i = 0; i + k <= n; ++i) if (t.substr(i, k) == t.substr(i + k, k)) s.insert(t.substr(i, 2 * k)); return s.size(); } }; |
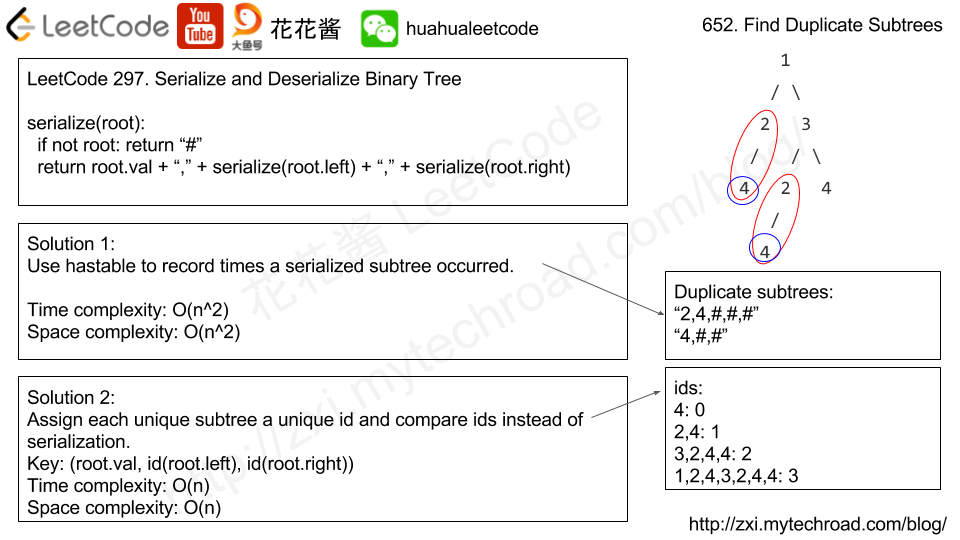
652. Find Duplicate SubtreesMedium730151FavoriteShare
Given a binary tree, return all duplicate subtrees. For each kind of duplicate subtrees, you only need to return the root node of any one of them.
Two trees are duplicate if they have the same structure with same node values.
Example 1:
The following are two duplicate subtrees:
1
/ \
2 3
/ / \
4 2 4
/
4
2
/
4
and
4
Therefore, you need to return above trees’ root in the form of a list.
Time complexity: O(n^2)
Space complexity: O(n^2)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// Author: Huahua // Runtime: 29 ms class Solution { public: vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) { unordered_map<string, int> counts; vector<TreeNode*> ans; serialize(root, counts, ans); return ans; } private: string serialize(TreeNode* root, unordered_map<string, int>& counts, vector<TreeNode*>& ans) { if (!root) return "#"; string key = to_string(root->val) + "," + serialize(root->left, counts, ans) + "," + serialize(root->right, counts, ans); if (++counts[key] == 2) ans.push_back(root); return key; } }; |
Solution 2: int id for each unique subtree
Time complexity: O(n)
Space complexity: O(n)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
// Author: Huahua // Runtime: 8 ms class Solution { public: vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) { unordered_map<long, pair<int,int>> counts; vector<TreeNode*> ans; getId(root, counts, ans); return ans; } private: int getId(TreeNode* root, unordered_map<long, pair<int,int>>& counts, vector<TreeNode*>& ans) { if (!root) return 0; long key = (static_cast<long>(static_cast<unsigned>(root->val)) << 32) + (getId(root->left, counts, ans) << 16) + getId(root->right, counts, ans); auto& p = counts[key]; if (p.second++ == 0) p.first = counts.size(); else if (p.second == 2) ans.push_back(root); return p.first; } }; |
https://leetcode.com/problems/employee-importance/description/
Problem:
ou are given a data structure of employee information, which includes the employee’s unique id, his importance value and his direct subordinates’ id.
For example, employee 1 is the leader of employee 2, and employee 2 is the leader of employee 3. They have importance value 15, 10 and 5, respectively. Then employee 1 has a data structure like [1, 15, [2]], and employee 2 has [2, 10, [3]], and employee 3 has [3, 5, []]. Note that although employee 3 is also a subordinate of employee 1, the relationship is not direct.
Now given the employee information of a company, and an employee id, you need to return the total importance value of this employee and all his subordinates.
Example 1:
|
1 2 3 4 5 |
Input: [[1, 5, [2, 3]], [2, 3, []], [3, 3, []]], 1 Output: 11 Explanation: Employee 1 has importance value 5, and he has two direct subordinates: employee 2 and employee 3. They both have importance value 3. So the total importance value of employee 1 is 5 + 3 + 3 = 11. |
Note:
Idea:
BFS / DFS

Time complexity: O(n)
Space complexity: O(n)
Solution:
C++ / BFS
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
// Author: Huahua // Running time: 13 ms class Solution { public: int getImportance(vector<Employee*> employees, int id) { unordered_map<int, Employee*> es; for (auto e : employees) es.emplace(e->id, e); queue<int> q; q.push(id); int sum = 0; while (!q.empty()) { int eid = q.front(); q.pop(); auto e = es[eid]; sum += e->importance; for (auto rid : e->subordinates) q.push(rid); } return sum; } }; |
C++ / DFS
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
class Solution { public: int getImportance(vector<Employee*> employees, int id) { unordered_map<int, Employee*> es; for (auto e : employees) es.emplace(e->id, e); return dfs(id, es); } private: int dfs(int id, const unordered_map<int, Employee*>& es) { const auto e = es.at(id); int sum = e->importance; for (int rid : e->subordinates) sum += dfs(rid, es); return sum; } }; |