The DNA sequence is composed of a series of nucleotides abbreviated as 'A', 'C', 'G', and 'T'.
For example, "ACGAATTCCG" is a DNA sequence.
When studying DNA, it is useful to identify repeated sequences within the DNA.
Given a string s that represents a DNA sequence, return all the 10-letter-long sequences (substrings) that occur more than once in a DNA molecule. You may return the answer in any order.
Example 1:
Input: s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT"
Output: ["AAAAACCCCC","CCCCCAAAAA"]
Example 2:
Input: s = "AAAAAAAAAAAAA"
Output: ["AAAAAAAAAA"]
Constraints:
1 <= s.length <= 105
s[i] is either 'A', 'C', 'G', or 'T'.
Solution: Hashtable
Store each subsequence into the hashtable, add it into the answer array when it appears for the second time.
Time complexity: O(n*l) Space complexity: O(n*l) -> O(n) / string_view
There are 4 type of letters, each can be encoded into 2 bits. We can represent the 10-letter-long string using 20 lowest bit of a int32. We can use int as key for the hashtable.
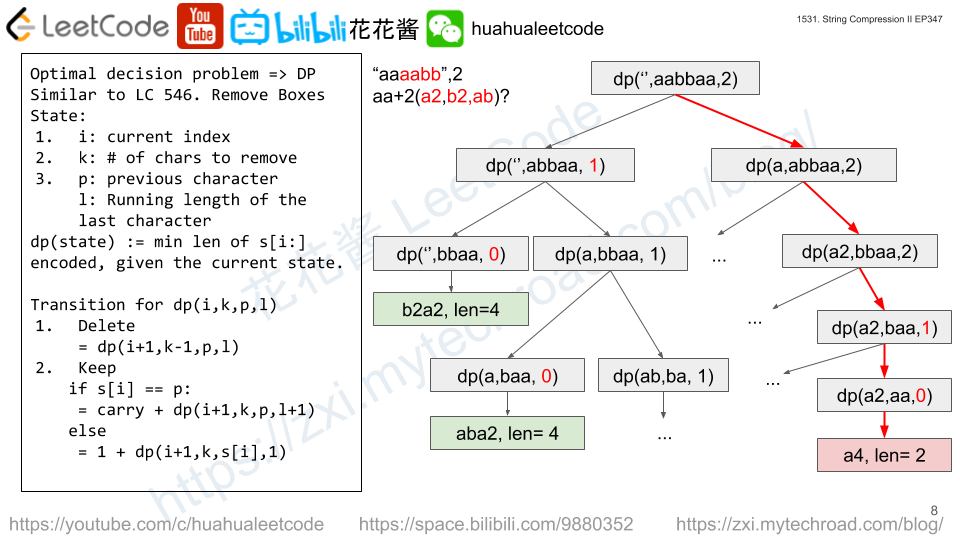
Run-length encoding is a string compression method that works by replacing consecutive identical characters (repeated 2 or more times) with the concatenation of the character and the number marking the count of the characters (length of the run). For example, to compress the string "aabccc" we replace "aa" by "a2" and replace "ccc" by "c3". Thus the compressed string becomes "a2bc3".
Notice that in this problem, we are not adding '1' after single characters.
Given a string s and an integer k. You need to delete at mostk characters from s such that the run-length encoded version of s has minimum length.
Find the minimum length of the run-length encoded version of s after deleting at most k characters.
Example 1:
Input: s = "aaabcccd", k = 2
Output: 4
Explanation: Compressing s without deleting anything will give us "a3bc3d" of length 6. Deleting any of the characters 'a' or 'c' would at most decrease the length of the compressed string to 5, for instance delete 2 'a' then we will have s = "abcccd" which compressed is abc3d. Therefore, the optimal way is to delete 'b' and 'd', then the compressed version of s will be "a3c3" of length 4.
Example 2:
Input: s = "aabbaa", k = 2
Output: 2
Explanation: If we delete both 'b' characters, the resulting compressed string would be "a4" of length 2.
Example 3:
Input: s = "aaaaaaaaaaa", k = 0
Output: 3
Explanation: Since k is zero, we cannot delete anything. The compressed string is "a11" of length 3.
Constraints:
1 <= s.length <= 100
0 <= k <= s.length
s contains only lowercase English letters.
Solution 0: Brute Force DFS (TLE)
Time complexity: O(C(n,k)) Space complexity: O(k)
C++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
classSolution{
public:
intgetLengthOfOptimalCompression(strings,intk){
constintn=s.length();
auto encode=[&]() -> int {
char p = '$';
intcount=0;
intlen=0;
for(charc:s){
if(c=='.')continue;
if(c!=p){
p=c;
count=0;
}
++count;
if(count<=2||count==10||count==100)
++len;
}
returnlen;
};
function<int(int,int)>dfs=[&](int start, int k) -> int {
if (start == n || k == 0) return encode();
intans=n;
for(inti=start;i<n;++i){
charc=s[i];
s[i]='.';// delete
ans=min(ans,dfs(i+1,k-1));
s[i]=c;
}
returnans;
};
returndfs(0,k);
}
};
Solution1: DP
State: i: the start index of the substring last: last char len: run-length k: # of chars that can be deleted.
base case: 1. k < 0: return inf # invalid 2. i >= s.length(): return 0 # done
Transition: 1. if s[i] == last: return carry + dp(i + 1, last, len + 1, k)
2. if s[i] != last: return min(1 + dp(i + 1, s[i], 1, k, # start a new group with s[i] dp(i + 1, last, len, k -1) # delete / skip s[i], keep it as is.
Time complexity: O(n^3*26) Space complexity: O(n^3*26)
C++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
intcache[101][27][101][101];
classSolution{
public:
intgetLengthOfOptimalCompression(strings,intk){
memset(cache,-1,sizeof(cache));
// Min length of compressioned string of s[i:]
// 1. last char is |last|
// 2. current run-length is len
// 3. we can delete k chars.
function<int(int,int,int,int)>dp=
[&](int i, int last, int len, int k) {
if (k < 0) return INT_MAX / 2;
if(i>=s.length())return0;
int& ans = cache[i][last][len][k];
if(ans!=-1)returnans;
if(s[i]-'a'==last){
// same as the previous char, no need to delete.
intcarry=(len==1||len==9||len==99);
ans=carry+dp(i+1,last,len+1,k);
}else{
ans=min(1+dp(i+1,s[i]-'a',1,k),// keep s[i]
dp(i+1,last,len,k-1));// delete s[i]
}
returnans;
};
returndp(0,26,0,k);
}
};
State compression
dp[i][k] := min len of s[i:] encoded by deleting at most k charchters.
dp[i][k] = min(dp[i+1][k-1] # delete s[i] encode_len(s[i~j] == s[i]) + dp(j+1, k – sum(s[i~j])) for j in range(i, n)) # keep
Time complexity: O(n^2*k) Space complexity: O(n*k)
C++
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// Author: Huahua
classSolution{
public:
intgetLengthOfOptimalCompression(strings,intk){
constintn=s.length();
vector<vector<int>>cache(n,vector<int>(k+1,-1));
function<int(int,int)>dp=[&](int i, int k) -> int {
if (k < 0) return n;
if(i+k>=n)return0;
int& ans = cache[i][k];
if(ans!=-1)returnans;
ans=dp(i+1,k-1);// delete
intlen=0;
intsame=0;
intdiff=0;
for(intj=i;j<n&& diff <= k;++j){
if(s[j]==s[i]&& ++same) {
if (same <= 2 || same == 10 || same == 100) ++len;
Given an array of integers representing the data, return whether it is a valid utf-8 encoding.
Note: The input is an array of integers. Only the least significant 8 bits of each integer is used to store the data. This means each integer represents only 1 byte of data.
Example 1:
data = [197, 130, 1], which represents the octet sequence: 11000101 10000010 00000001.
Return true.
It is a valid utf-8 encoding for a 2-bytes character followed by a 1-byte character.
Example 2:
data = [235, 140, 4], which represented the octet sequence: 11101011 10001100 00000100.
Return false.
The first 3 bits are all one's and the 4th bit is 0 means it is a 3-bytes character.
The next byte is a continuation byte which starts with 10 and that's correct.
But the second continuation byte does not start with 10, so it is invalid.
Solution: Bit Operation
Check the first byte of a character and find out the number of bytes (from 0 to 3) left to check. The left bytes must start with 0b10.
Given an array of characters, compress it in-place.
The length after compression must always be smaller than or equal to the original array.
Every element of the array should be a character (not int) of length 1.
After you are done modifying the input array in-place, return the new length of the array.
Follow up:
Could you solve it using only O(1) extra space?
Example 1:
Input:
["a","a","b","b","c","c","c"]
Output:
Return 6, and the first 6 characters of the input array should be: ["a","2","b","2","c","3"]
Explanation:
"aa" is replaced by "a2". "bb" is replaced by "b2". "ccc" is replaced by "c3".
Example 2:
Input:
["a"]
Output:
Return 1, and the first 1 characters of the input array should be: ["a"]
Explanation:
Nothing is replaced.
Example 3:
Input:
["a","b","b","b","b","b","b","b","b","b","b","b","b"]
Output:
Return 4, and the first 4 characters of the input array should be: ["a","b","1","2"].
Explanation:
Since the character "a" does not repeat, it is not compressed. "bbbbbbbbbbbb" is replaced by "b12".
Notice each digit has it's own entry in the array.