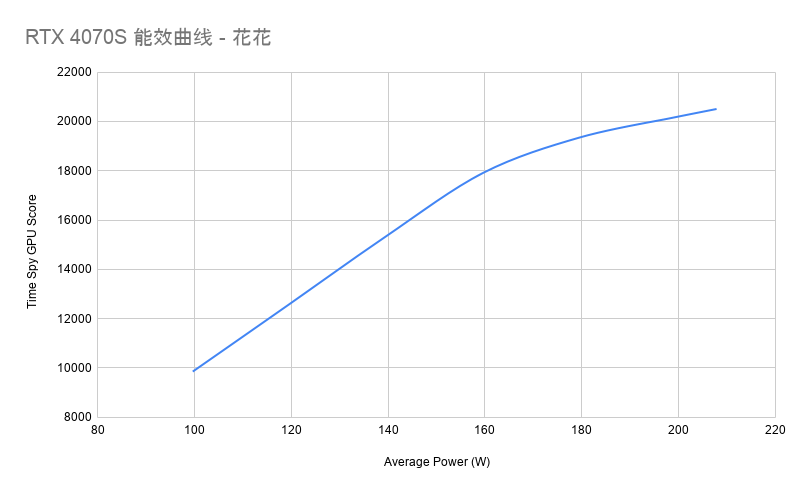
这次测试的目标很简单:不只看 RTX 4070 Super 满功耗能跑多少分,而是看看它在不同功耗限制下,性能和功耗之间到底怎么变化。
很多显卡在接近默认功耗上限时,最后一截性能往往要付出明显更高的功耗和噪音代价。4070 Super 本身能效已经不错,所以我更关心的问题是:如果把功耗限制从默认的 220W 一路降到 100W,它的 Time Spy 图形性能会怎么掉?哪一个功耗点最适合日用?
先说结论:在我这张卡和这套测试环境里,160W 是最高能效点,180W 是更适合日用的性能/功耗平衡点。200W 以上仍然能涨分,但收益递减已经很明显。
测试方法
测试使用 3DMark Time Spy。每一档功耗限制下运行一次 Time Spy,并记录 GPU 日志。平均功耗和平均频率不是整段日志直接平均,而是只统计 Time Spy 两段 Graphics Test 中的高负载区间,避免菜单、加载、空闲段把结果稀释。
功耗限制通过 NVIDIA 的 power limit 设置,测试区间为 100W 到 220W。日志中记录了 GPU 功耗、GPU 利用率、核心频率和显存频率。
简单来说,这篇文章里的 Avg Power 更接近“跑 Time Spy GPU 测试时显卡实际吃了多少电”,而不是整场测试从开始到结束的粗略平均。
测试数据
| Power Limit | Time Spy GPU Score | Avg Power (W) | Time Spy CPU | Graphics Test 1 | Graphics Test 2 | Avg GPU Freq | Avg Mem Freq |
|---|---|---|---|---|---|---|---|
| 100W | 9855 | 99.64 | 16418 | 65.54 | 55.53 | 1042 | 10501 |
| 120W | 12564 | 119.42 | 16437 | 84.07 | 70.43 | 1369 | 10501 |
| 140W | 15301 | 139.28 | 16240 | 102.46 | 85.72 | 1740 | 10501 |
| 160W | 17914 | 159.63 | 16314 | 120.19 | 100.19 | 2179 | 10501 |
| 180W | 19343 | 179.46 | 16475 | 127.31 | 109.96 | 2465 | 10501 |
| 200W | 20133 | 198.33 | 16358 | 132.41 | 114.53 | 2651 | 10501 |
| 220W | 20506 | 207.87 | 16396 | 133.18 | 117.93 | 2751 | 10501 |
能效分析
如果只看 Time Spy GPU 分数,220W 当然最高,GPU 分数为 20506。但这并不是完整故事。把 GPU 分数除以平均功耗后,就能看到每瓦性能的变化:
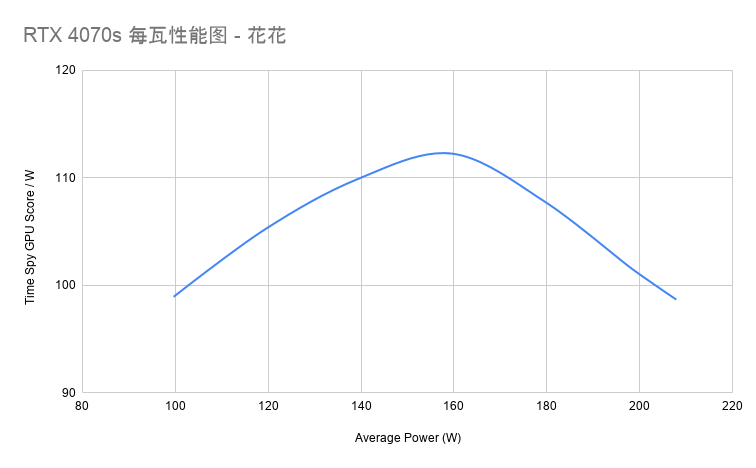
这里最醒目的点是 160W。它的 GPU 分数是 17914,平均功耗 159.63W,算下来约 112.2 分/W,是这组测试里的最高能效点。
再看 180W,它的 GPU 分数提升到 19343,平均功耗 179.46W。相比 160W,多吃了约 19.8W,GPU 分数多了 1429 分,这一段提升仍然比较划算。
但从 180W 往上,味道就变了。180W 到 200W,平均功耗增加约 18.9W,GPU 分数只增加 790 分;200W 到 220W,实际平均功耗增加约 9.5W,GPU 分数只增加 373 分。换句话说,200W 以上更多是在榨最后一点跑分,能效已经明显下降。
不同功耗档的感觉
100W – 140W:能跑,但性能损失比较明显
100W 到 140W 的能效并不差,特别是 120W 和 140W,相比 100W 有明显提升。不过这几个档位的平均 GPU 频率偏低,Time Spy GPU 分数也掉得比较多。如果目标是极限省电、低热量、低噪音,它们有意义;但如果是主力游戏档,我觉得会有点压得太狠。
160W:最高能效点
160W 是这次测试里最漂亮的点。它拿到了 17914 的 Time Spy GPU 分数,平均 GPU 频率约 2179MHz,平均功耗约 159.63W。相比 220W,性能大约少 12.6%,但平均功耗低了约 48W。
这就是典型的安静省电档:性能仍然不错,但热量、风扇压力和整机功耗都会舒服很多。
180W:我更愿意日用的平衡点
如果只选一个日用档,我会更偏向 180W。它的 GPU 分数是 19343,已经非常接近 200W 和 220W 档,但功耗仍然控制在 180W 左右。
相比 220W,180W 的 GPU 分数少约 5.7%,但平均功耗少了约 28W。这个交换非常合理,尤其是对一张本来就不算高功耗的中高端卡来说,180W 很像一个“该有的性能都有,但不硬榨”的位置。
200W – 220W:跑分更高,但收益递减
200W 和 220W 的分数当然更高,平均 GPU 频率也更高。但从数据看,220W 并没有比 200W 拉开太多,Time Spy GPU 分数只高 373 分。
如果目标是跑最高分,220W 没问题;但如果目标是日常游戏体验、噪音和温度平衡,我不觉得默认满功耗是最优解。
降压超频:0.90V / 0.925V 表现
在基础功耗测试之后,我又简单补测了两组 VF Curve 降压定频设置,主要想看看 4070 Super 在 180W 左右能不能用更低电压换到更高、更稳定的核心频率。
这两组设置分别是:
| 设置 | Time Spy Score | Avg Power (W) | Avg GPU Freq | 备注 |
|---|---|---|---|---|
| 2550MHz @ 0.90V | 19606 | 175.73 | 2550 | 更低电压,功耗控制更好 |
| 2640MHz @ 0.925V | 20249 | 182.09 | 2640 | 频率更高,同时显存也更高 |
从日志看,2550MHz @ 0.90V 这组已经比原始 180W 档更好看。之前 180W stock 的平均功耗约 179.46W,平均 GPU 频率约 2465MHz;而这组降压定频之后,平均功耗降到 175.73W,平均 GPU 频率反而稳定在 2550MHz。
这说明 4070 Super 在这个区间确实有降压优化空间。相比单纯拉功耗上限,VF Curve 能把显卡固定在一个更高效的电压/频率点上。
2640MHz @ 0.925V 这组则更偏性能档。甚至超过了默认200W档的分数,而它的平均功耗仅为 182.09W,全程都没有碰到功耗墙,GPU 频率能稳定在 2640MHz,显存频率也小超到了 11501MHz。
所以目前看下来,我会把这两组理解成:
| Profile | 定位 |
|---|---|
2550MHz @ 0.90V | 安静省电档,适合追求低功耗和低噪音 |
2640MHz @ 0.925V | 日用性能档,适合替代默认 180W / 200W 设置 |
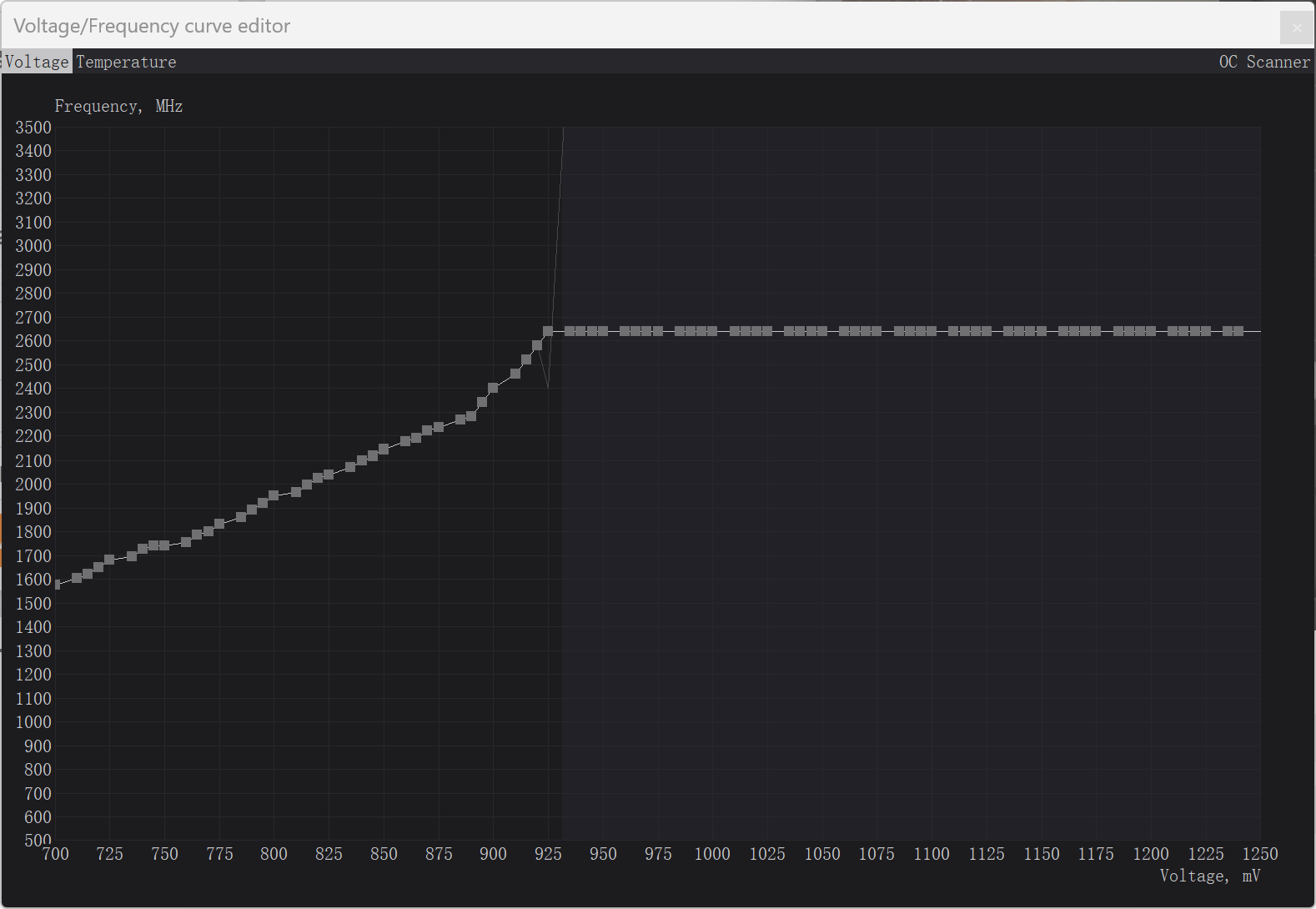
2640MHz@0.925V VF曲线
结论
这张 RTX 4070 Super 的能效曲线很清楚:它不是不能跑 220W,而是没必要一直跑 220W。
如果追求最高能效,160W 是最甜的点。它拿到最高的每瓦性能,适合安静、省电、低温的日常游戏环境。
如果追求更好的日用体验,180W 是我更推荐的平衡点。它比 160W 多给了不少性能,又比 220W 少吃明显功耗,实际体验上会更接近满血卡。
200W 和 220W 依然有意义,但更多适合跑分或者不在乎功耗噪音的场景。对我来说,4070 Super 真正好玩的地方不是把功耗拉满,而是找到 160W 和 180W 这两个甜点,再配合显存 OC 和 VF Curve,把性能、功耗和噪音调到一个舒服的位置。
最后提醒一下,这些数据只代表我这张卡和这套测试环境。不同品牌、散热、BIOS、驱动版本和机箱风道都会影响结果。但大方向应该类似:4070 Super 在 160W 到 180W 区间,有非常值得挖的能效空间。

