Problem:
Given two sentences words1, words2 (each represented as an array of strings), and a list of similar word pairs pairs, determine if two sentences are similar.
For example, words1 = ["great", "acting", "skills"] and words2 = ["fine", "drama", "talent"] are similar, if the similar word pairs are pairs = [["great", "good"], ["fine", "good"], ["acting","drama"], ["skills","talent"]].
Note that the similarity relation is transitive. For example, if “great” and “good” are similar, and “fine” and “good” are similar, then “great” and “fine” are similar.
Similarity is also symmetric. For example, “great” and “fine” being similar is the same as “fine” and “great” being similar.
Also, a word is always similar with itself. For example, the sentences words1 = ["great"], words2 = ["great"], pairs = [] are similar, even though there are no specified similar word pairs.
Finally, sentences can only be similar if they have the same number of words. So a sentence like words1 = ["great"] can never be similar to words2 = ["doubleplus","good"].
Note:
- The length of
words1andwords2will not exceed1000. - The length of
pairswill not exceed2000. - The length of each
pairs[i]will be2. - The length of each
words[i]andpairs[i][j]will be in the range[1, 20].
题目大意:
给你两个句子(由单词数组表示)和一些近义词对,问你这两个句子是否相似,即每组相对应的单词都要相似。
注意相似性可以传递,比如只给你”great”和”fine”相似、”fine”和”good”相似,能推断”great”和”good”也相似。
Idea:
DFS / Union Find
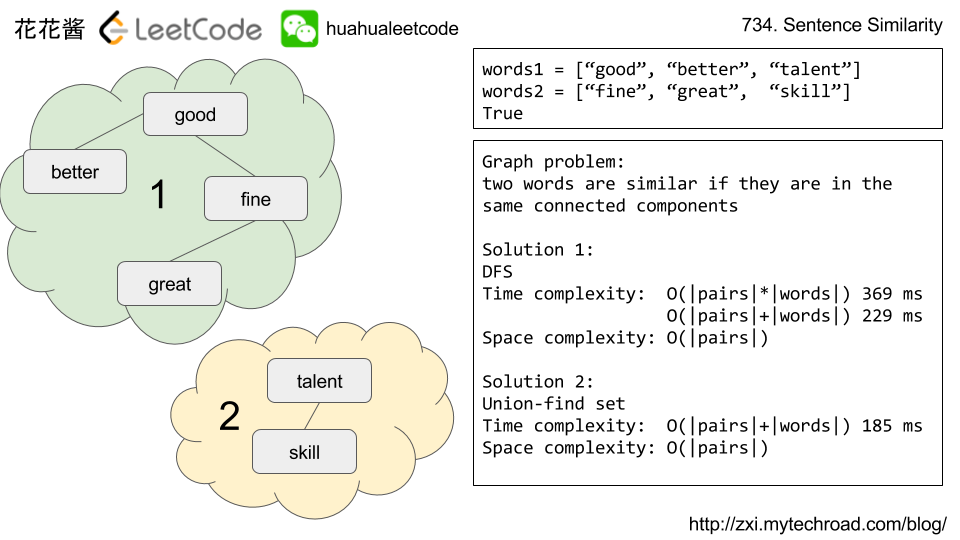
Solution1:
Time complexity: O(|Pairs| * |words1|)
Space complexity: O(|Pairs|)
C++ / DFS
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
// Author: Huahua // Runtime: 346 ms class Solution { public: bool areSentencesSimilarTwo(vector<string>& words1, vector<string>& words2, vector<pair<string, string>>& pairs) { if (words1.size() != words2.size()) return false; g_.clear(); for (const auto& p : pairs) { g_[p.first].insert(p.second); g_[p.second].insert(p.first); } unordered_set<string> visited; for (int i = 0; i < words1.size(); ++i) { visited.clear(); if (!dfs(words1[i], words2[i], visited)) return false; } return true; } private: bool dfs(const string& src, const string& dst, unordered_set<string>& visited) { if (src == dst) return true; visited.insert(src); for (const auto& next : g_[src]) { if (visited.count(next)) continue; if (dfs(next, dst, visited)) return true; } return false; } unordered_map<string, unordered_set<string>> g_; }; |
Time complexity: O(|Pairs| + |words1|)
Space complexity: O(|Pairs|)
C++ / DFS Optimized
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
// Author: Huahua // Runtime 229 ms class Solution { public: bool areSentencesSimilarTwo(vector<string>& words1, vector<string>& words2, vector<pair<string, string>>& pairs) { if (words1.size() != words2.size()) return false; g_.clear(); ids_.clear(); for (const auto& p : pairs) { g_[p.first].insert(p.second); g_[p.second].insert(p.first); } int id = 0; for (const auto& p : pairs) { if(!ids_.count(p.first)) dfs(p.first, ++id); if(!ids_.count(p.second)) dfs(p.second, ++id); } for (int i = 0; i < words1.size(); ++i) { if (words1[i] == words2[i]) continue; auto it1 = ids_.find(words1[i]); auto it2 = ids_.find(words2[i]); if (it1 == ids_.end() || it2 == ids_.end()) return false; if (it1->second != it2->second) return false; } return true; } private: bool dfs(const string& curr, int id) { ids_[curr] = id; for (const auto& next : g_[curr]) { if (ids_.count(next)) continue; if (dfs(next, id)) return true; } return false; } unordered_map<string, int> ids_; unordered_map<string, unordered_set<string>> g_; }; |
Solution2:
Time complexity: O(|Pairs| + |words1|)
Space complexity: O(|Pairs|)
C++ / Union Find
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
// Author: Huahua // Runtime: 219 ms class UnionFindSet { public: bool Union(const string& word1, const string& word2) { const string& p1 = Find(word1, true); const string& p2 = Find(word2, true); if (p1 == p2) return false; parents_[p1] = p2; return true; } const string& Find(const string& word, bool create = false) { if (!parents_.count(word)) { if (!create) return word; return parents_[word] = word; } string w = word; while (w != parents_[w]) { parents_[w] = parents_[parents_[w]]; w = parents_[w]; } return parents_[w]; } private: unordered_map<string, string> parents_; }; class Solution { public: bool areSentencesSimilarTwo(vector<string>& words1, vector<string>& words2, vector<pair<string, string>>& pairs) { if (words1.size() != words2.size()) return false; UnionFindSet s; for (const auto& pair : pairs) s.Union(pair.first, pair.second); for (int i = 0; i < words1.size(); ++i) if (s.Find(words1[i]) != s.Find(words2[i])) return false; return true; } }; |
C++ / Union Find, Optimized
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
// Author: Huahua // Runtime: 175 ms (< 98.45%) class UnionFindSet { public: UnionFindSet(int n) { parents_ = vector<int>(n + 1, 0); ranks_ = vector<int>(n + 1, 0); for (int i = 0; i < parents_.size(); ++i) parents_[i] = i; } bool Union(int u, int v) { int pu = Find(u); int pv = Find(v); if (pu == pv) return false; if (ranks_[pu] > ranks_[pv]) { parents_[pv] = pu; } else if (ranks_[pv] > ranks_[pu]) { parents_[pu] = pv; } else { parents_[pu] = pv; ++ranks_[pv]; } return true; } int Find(int id) { if (id != parents_[id]) parents_[id] = Find(parents_[id]); return parents_[id]; } private: vector<int> parents_; vector<int> ranks_; }; class Solution { public: bool areSentencesSimilarTwo(vector<string>& words1, vector<string>& words2, vector<pair<string, string>>& pairs) { if (words1.size() != words2.size()) return false; UnionFindSet s(pairs.size() * 2); unordered_map<string, int> indies; // word to index for (const auto& pair : pairs) { int u = getIndex(pair.first, indies, true); int v = getIndex(pair.second, indies, true); s.Union(u, v); } for (int i = 0; i < words1.size(); ++i) { if (words1[i] == words2[i]) continue; int u = getIndex(words1[i], indies); int v = getIndex(words2[i], indies); if (u < 0 || v < 0) return false; if (s.Find(u) != s.Find(v)) return false; } return true; } private: int getIndex(const string& word, unordered_map<string, int>& indies, bool create = false) { auto it = indies.find(word); if (it == indies.end()) { if (!create) return INT_MIN; int index = indies.size(); indies.emplace(word, index); return index; } return it->second; } }; |
Related Problems:
请尊重作者的劳动成果,转载请注明出处!花花保留对文章/视频的所有权利。
如果您喜欢这篇文章/视频,欢迎您捐赠花花。
If you like my articles / videos, donations are welcome.

huahualeetcode


Be First to Comment